
Interrupción global debido a una actualización de CrowdStrike el viernes
La historia de cómo CrowdStrike lanzó una actualización un viernes y derribó miles, decenas de miles o tal vez incluso cientos de miles de computadoras en todo el mundo.

¿Alguna vez has oído la regla tácita: “Nunca publiques un programa los viernes”? Nosotros sí, pero CrowdStrike no. Publicaron un pequeño controlador un viernes por la mañana normal, lo que se convirtió en la causa de una gran interrupción del servicio en todo el mundo.
Una actualización incorrecta de la solución EDR (Endpoint Detection and Response) de CrowdStrike ha afectado a dispositivos Windows de todo el mundo, provocando la pantalla azul de la muerte (BSOD) en los usuarios corporativos . El fallo ha afectado, por ejemplo, a los sistemas de información de aeropuertos de Estados Unidos, España, Alemania, Países Bajos y otros países.
¿Quién más se vio afectado por el lanzamiento del viernes de CrowdStrike y cómo revertir el bloqueo de computadoras? Todo en esta publicación…
Qué pasó
Todo empezó a primera hora de la mañana del viernes, cuando usuarios corporativos de todo el mundo informaron de problemas con Windows. En un primer momento, se atribuyó la culpa a un fallo en Microsoft Azure, pero más tarde CrowdStrike confirmó que la causa principal se encontraba en el controlador csagent.sys o C-00000291*.sys de su CrowdStrike EDR. Y fue este controlador el que provocó una gran cantidad de fotos absurdas de la oficina que mostraban las (temidas) pantallas azules.
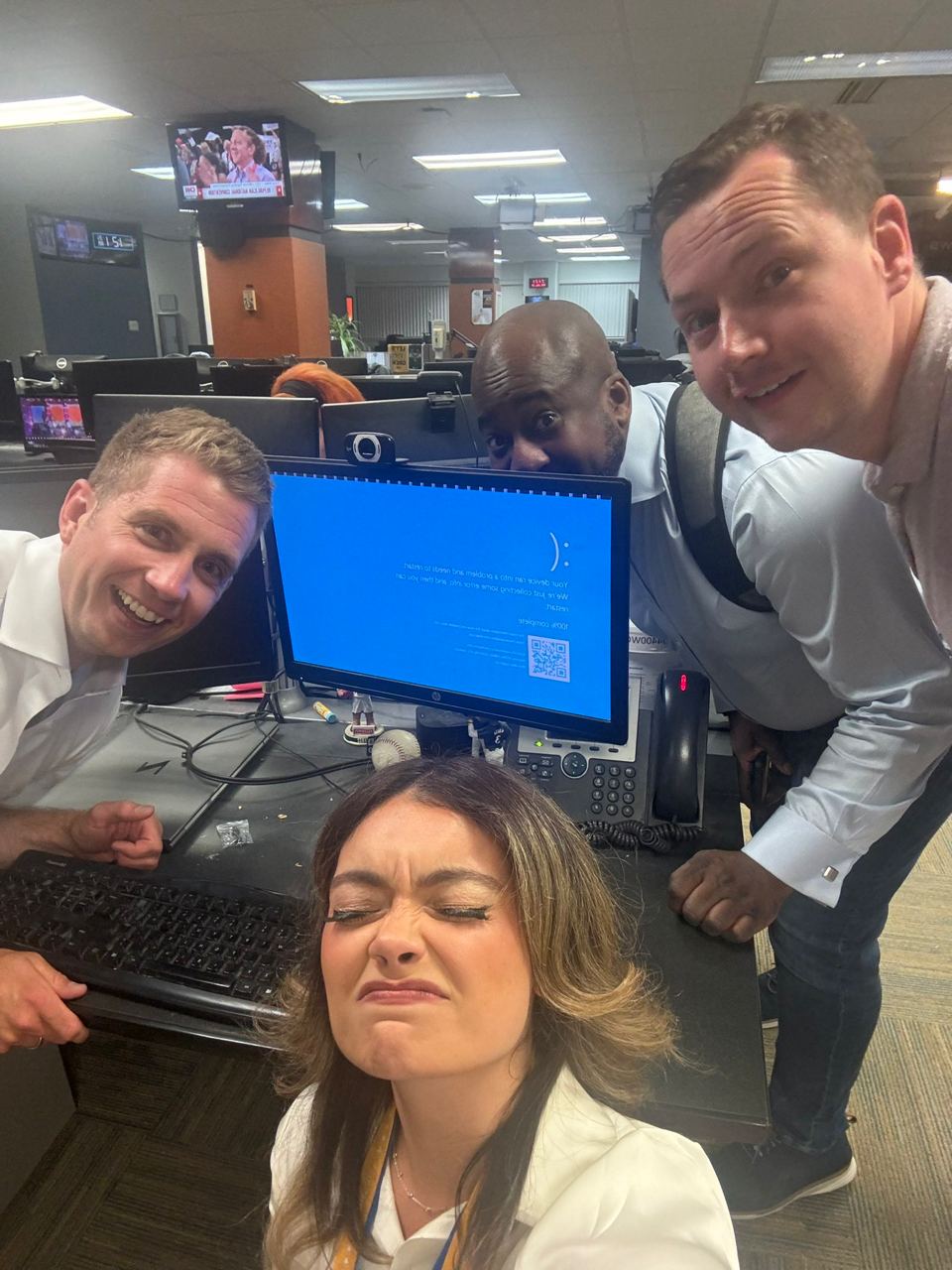
Pantalla azul de la muerte en todas las computadoras = día libre para los linieros del aeropuerto
Si quisiéramos enumerar a todos los afectados por esta interrupción, una lista así no cabría en este artículo (ni en decenas de ellos). Por eso, en su lugar, cubriremos brevemente a las principales víctimas de la negligencia de CrowdStrike. Las compañías aéreas, los aeropuertos y las personas que quieren volver a casa o irse de vacaciones tan esperadas fueron los más afectados:
- El aeropuerto de Heathrow de Londres, como muchos otros, anunció retrasos en los vuelos debido a un fallo tecnológico;
- Scandinavian Airlines publicó un aviso en su sitio web en el que se indica que “algunos clientes pueden experimentar dificultades con sus reservas debido a un problema informático que afecta a varios países. SAS está en pleno funcionamiento, pero se esperan retrasos”;
- En Nueva Zelanda, los sistemas bancarios, de comunicaciones y de transporte están experimentando problemas.
Varios centros médicos, cadenas de tiendas, el metro de Nueva York, el banco más grande de Sudáfrica y muchas otras organizaciones que hacen que la vida sea más cómoda y conveniente a diario se vieron afectados. La lista completa de los afectados por el apagón que podemos encontrar está aquí , y crece minuto a minuto.
Como arreglarlo
En esta etapa, es bastante problemático estimar cuánto tiempo tomará restaurar por completo los equipos afectados en todo el mundo. Las cosas se complican por el hecho de que los usuarios deben reiniciar manualmente sus equipos en modo seguro. Y en las grandes corporaciones, esto suele ser imposible de hacer por su cuenta sin la ayuda de un administrador de sistemas.
Sin embargo, aquí están las instrucciones sobre cómo deshacerse de la pantalla azul de la muerte causada por la actualización del controlador de CrowdStrike:
- Inicie su computadora en modo seguro;
- Vaya a C:\Windows\System32\drivers\CrowdStrike ;
- Localice y elimine el archivo csagent.sys o C-00000291*.sys ;
- Reinicie su computadora en modo normal.
Y mientras sus administradores de sistemas hacen esto, usted podría utilizar un truco que ha surgido hoy en la India: los empleados de uno de los aeropuertos del país han comenzado a completar las tarjetas de embarque… manualmente.

La India no está demasiado preocupada por la disrupción global.
Cómo se podría haber evitado el fracaso
Evitar esta situación debería haber sido sencillo. En primer lugar, la actualización no debería haberse publicado un viernes. Esto se debe a una regla que todos en la industria conocen desde el año 2000: si ocurre un error, hay muy poco tiempo para solucionarlo antes del fin de semana, por lo que los administradores de sistemas de todas las empresas afectadas deben trabajar durante el fin de semana para solucionar los problemas.
Es importante ser lo más responsable posible con la calidad de las actualizaciones que se lanzan. En Kaspersky, lanzamos un programa en 2009 para evitar fallos masivos como este en nuestros clientes y pasamos una auditoría SOC 2 , lo que confirma la seguridad de nuestros procesos internos. Desde hace 15 años, cada actualización se somete a pruebas de rendimiento de varios niveles en varias configuraciones y versiones de sistema operativo. Esto nos permite identificar problemas potenciales con antelación y resolverlos en el momento.
Se debe seguir el principio de lanzamientos granulares. Las actualizaciones se deben distribuir gradualmente, no todas a la vez a todos los clientes. Este enfoque nos permite reaccionar de inmediato y detener una actualización si es necesario. Si nuestros usuarios tienen un problema, lo registramos y su solución se convierte en una prioridad en todos los niveles de la empresa.
Al igual que con los incidentes de ciberseguridad, además de reparar los daños visibles, es necesario encontrar la causa raíz para evitar que este tipo de problemas se repitan en el futuro. Es necesario comprobar la operatividad y los errores de las actualizaciones de software en la infraestructura de prueba antes de implementarlas en la infraestructura de «combate» de la empresa, e implementar los cambios de forma gradual, realizando un seguimiento continuo de posibles fallos.
La gestión de incidentes debe basarse en un enfoque integrado para crear protección a partir de un proveedor confiable con los requisitos internos más estrictos en materia de seguridad, calidad y disponibilidad de sus servicios. La base de este trabajo puede ser la línea de soluciones Kaspersky Next . Esto ayudará a su empresa no solo a mantenerse a flote, sino también a aumentar la eficiencia de su sistema de seguridad de la información. Esto se puede hacer de forma gradual (aumentando la protección paso a paso) o de una sola vez. Proteja su infraestructura hoy con nosotros para que la próxima interrupción global del servicio no afecte a sus clientes.
Y nosotros, por nuestra parte, podemos ayudarte a tomar esta decisión: cámbiate a Kaspersky y obtén dos años de Kaspersky Next EDR Optimum por el precio de uno . ¡Experimenta lo máximo en protección cibernética sólida y confiable!
Fuente: www.kaspersky.com