Un desarrollo del MIT permite doblar el rendimiento del protocolo TCP
Seguro que muchos lo sabéis, aunque no penséis en ello: el protocolo TCP (parte fundamental del par TCP/IP) es parte fundamental de nuestras vidas digitales. Ahora unos científicos del MIT han ideado una forma de adaptarlo a los tiempos y mejorar su rendimiento.
Este protocolo tiene su origen en los años 70, pero mucho ha cambiado en las redes de datos desde entonces. Se han utilizado distintos algoritmos para tratar de maximizar su rendimiento, y por ejemplo mientras que en Linux el algoritmo Cubic es el elegido por defecto, en Windows el algoritmo es el llamado Compound. En el MIT tienen un sustituto para los dos. Su nombre: Remy.
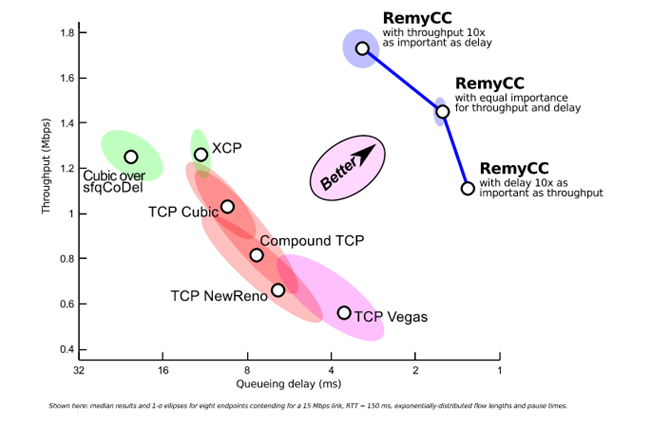
Una de las claves de este algoritmo es que “aprende” del comportamiento de la red y se adapta a ese comportamiento, dando mayor relevancia al throughput sobre la latencia o viceversa según sea necesario. De hecho, Remy es capaz de doblar el throughput y reducir a la mitad la latencia con respecto a Compound, mientras que puede incrementar en un 70% el throughput y reducir un 33% la latencia en comparación con Cubic.
El ejemplo más claro de ese comportamiento estaría en una situación en la que un usuario quisiera subir un vídeo de 1 GB a YouTube y otro quisiera hacer lo propio con otro vídeo de 5 GB. Remy sería capaz de detectar y dar solución al problema, dándole prioridad al usuario que sube el fichero de menor tamaño para luego dedicar todos los recursos al segundo.
Los desarrolladores de Remy explicaban que en TCP la pérdida de paquetes se atribuye a congestión en la red y eso provoca la reducción de la tasa de transmisión, algo que muchos desarrolladores han implementado en sus algoritmos. Con Remy todo es distinto:
Creemos que la mejor forma de dar respuesta a esta pregunta es evitarle el diseño de mecanismos algorítmicos específicos a los diseñadores humanos (sin importar lo sofisticados que sean) y hacer que el algoritmo que se aplique de extremo a extremo sea función del comportamiento general deseado.
Los desarrolladores no pueden predecir cuál será el impacto en Internet como conjunto si Remy acaba siendo usado, pero parece que este algoritmo es realmente prometedor. Ellos mismos confiesan que han tratado de crear algoritmos superiores a los que genera Remy sin éxito, y creen que su descubrimiento es prometedor. De momento el código está disponible en GitHub para quien quiera aplicarlo en sus sistemas.
Fuente: somoslibres.org